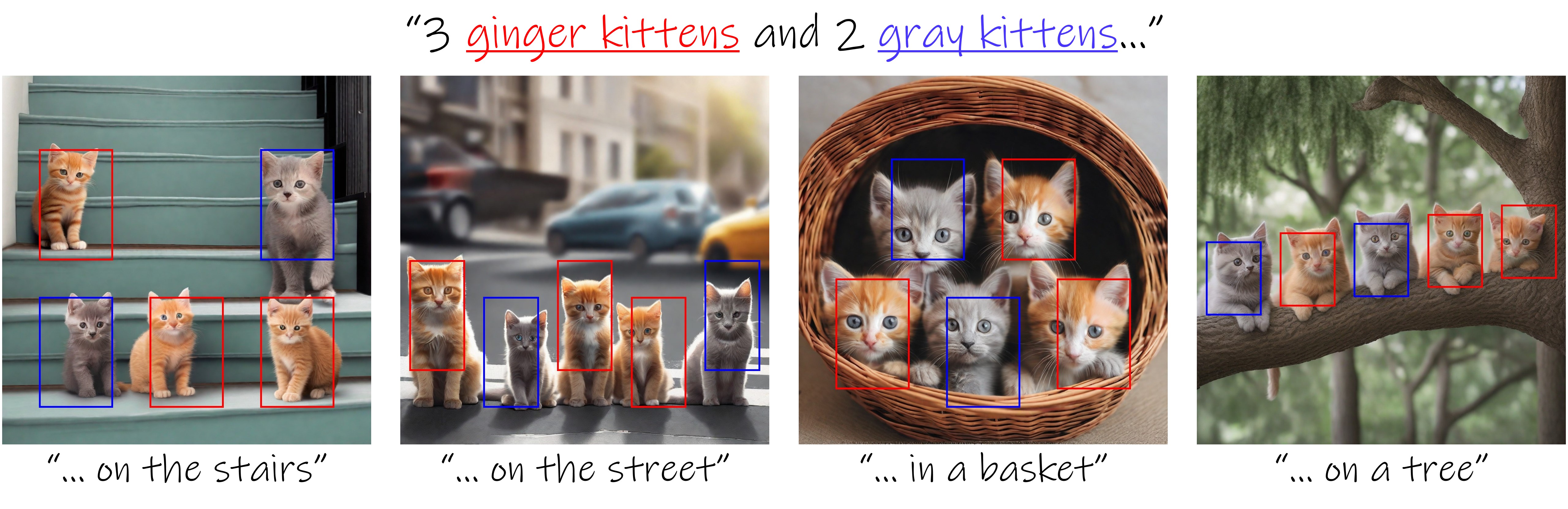









Text-to-image diffusion models have an unprecedented ability to generate diverse and high-quality images. However, they often struggle to faithfully capture the intended semantics of complex input prompts that include multiple subjects. Recently, numerous layout-to-image extensions have been introduced to improve user control, aiming to localize subjects represented by specific tokens. Yet, these methods often produce semantically inaccurate images, especially when dealing with multiple semantically or visually similar subjects. In this work, we study and analyze the causes of these limitations. Our exploration reveals that the primary issue stems from inadvertent semantic leakage between subjects in the denoising process. This leakage is attributed to the diffusion model’s attention layers, which tend to blend the visual features of different subjects. To address these issues, we introduce Bounded Attention, a training-free method for bounding the information flow in the sampling process. Bounded Attention prevents detrimental leakage among subjects and enables guiding the generation to promote each subject's individuality, even with complex multi-subject conditioning. Through extensive experimentation, we demonstrate that our method empowers the generation of multiple subjects that better align with given prompts and layouts.
We focus our analysis on semantically similar subjects, like a ''kitten'' and a ''puppy''.
Let x1 and x2 be 2D latent coordinates corresponding to two semantically similar subjects in the generated image. Intuitively, we expect that along the denoising process, the attention queries corresponding to these pixels, Q[x1] and Q[x2], will be similar and hence also their attention responses. This, in turn, implies that they will share semantic information from the attention layers, a phenomenon we refer to as semantic leakage.
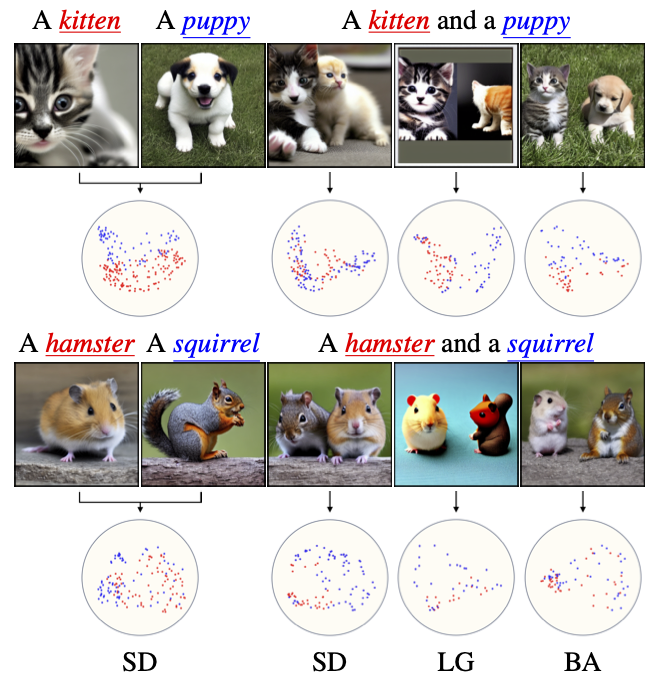
Here, We demonstrate the emergence of semantic leakage at the cross-attention layers. We show two examples: a puppy a kitten, and a hamster and a squirrel. In the two leftmost columns, the subjects were generated separately using Stable Diffusion (SD). In the right three columns, we generate a single image with the two subjects using three different methods: Stable Diffusion (SD), Layout Guidance (LG), and Bounded Attention (BA, ours). Under each row, we plot the two first principal components of the cross-attention queries. The level of separation between the red and blue dots in the plots reveals the semantic similarity of the two forming subjects.
The leftmost plot, in which the two subjects were generated separately, serves as a reference point to the relation between the queries when there is no leakage. As can be seen in the reference plots, the kitten and puppy queries share some small overlap, and the hamster and squirrel queries are mixed together.
Vanilla SD truggles to adequately generate the two subjects within the same image. This is apparent by the visual leakage between the two subjects, along with the blending of their respective queries.
LG optimizes the latent to have attention peaks for each noun token at their corresponding region. Its optimization objective implicitly encourages the separation between subjects' cross-attention queries, even though they should maintain their semantic similarity. This leads to artifacts and quality degradation.
Our approach preserves the feature distribution of the subjects' queries, and successfully generates the two subjects, even when the queries are as mixed as in the hamster and the squirrel.
In the paper we also demonstrate that semantic leakage can occur in the self-attention layers, and even between semantically dissimilar subjects!
Bounded Attention operates in two modes: guidance and denoising. In each mode, strict constraints are imposed to bound the attention of each subject solely to itself and, possibly, to the background, thereby preventing any influence from other subjects' features.
In guidance mode, we minimize a loss that encourages each subject's attention to concentrate within its corresponding bounding box. When calculating this loss, we mask the other bounding boxes, to prevent artifacts introduced by forcing subject queries to be far apart.
During the denoising step, we confine the attention of each subject solely to its bounding box, along with the background in the self-attention. This strategy effectively prevents feature leakage while maintaining the natural immersion of the subject within the image.
To demonstrate each of these modes, we show the attention map of a specific key, marked with a star. For the cross-attention map, we show the key corresponding to the ''kitten'' token, and for the self-attention map, we show a key that lies in the kitten's target bounding box.
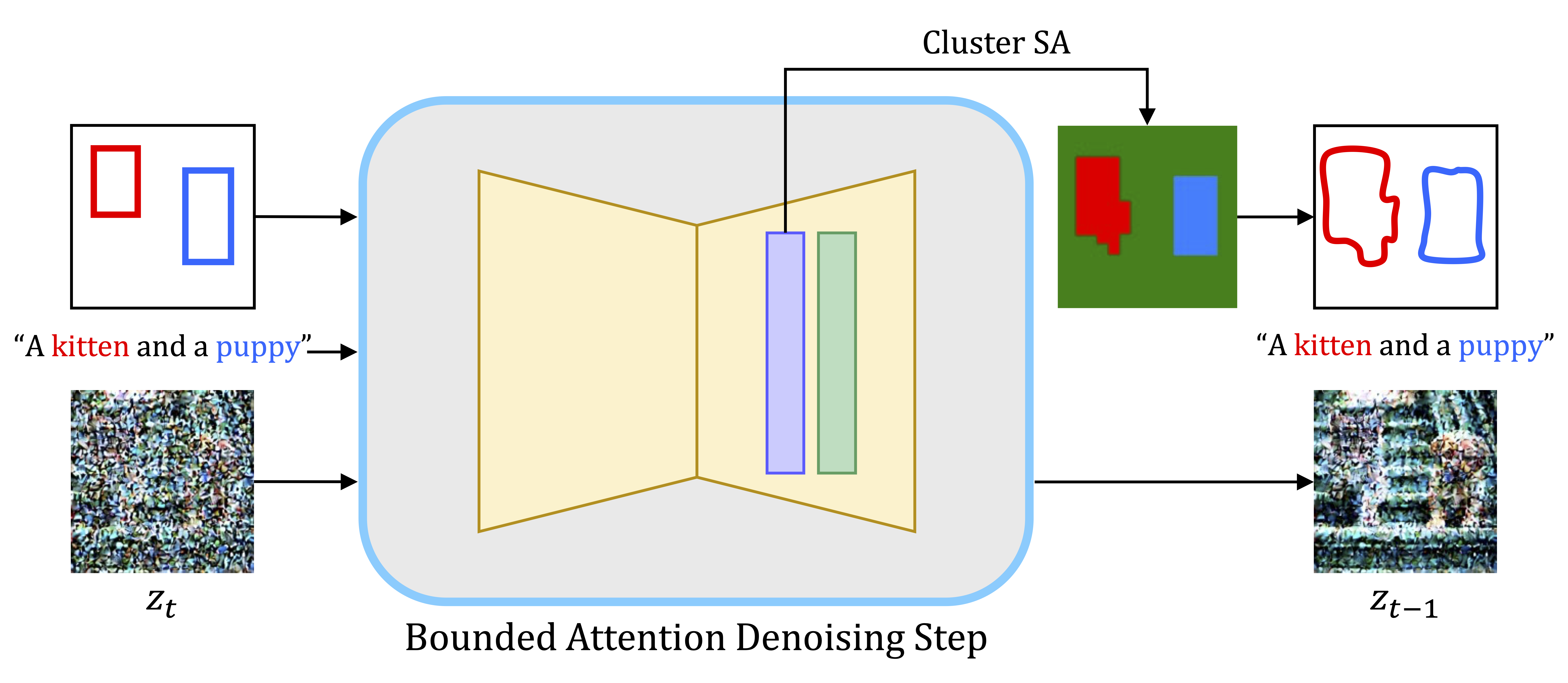
We find that coarse masking in later stages may degrade image quality and result in noticeable stitching. To address this, after the optimization phase, we replace each bounding box with a fine segmentation mask obtained by periodically clustering the self-attention maps.

Bounded Attention utilizes these masks to align the evolving image structure (represented by the self-attention maps) with its semantics (reflected by the cross-attention maps). Eemploying this technique enhances the robustness of our method to seed selection, ensuring proper semantics even when subjects extend beyond their initial confines.
@misc{dahary2024yourself,
title={Be Yourself: Bounded Attention for Multi-Subject Text-to-Image Generation},
author={Omer Dahary and Or Patashnik and Kfir Aberman and Daniel Cohen-Or},
year={2024},
eprint={2403.16990},
archivePrefix={arXiv},
primaryClass={cs.CV}
}